
Price oracle
https://members.delphidigital.io/reports/the-oracle-report-of-delphi/
Delphi Digital, Jun 2021

Oracles are important. For those already familiar with crypto, we don’t need to waste time in this report telling you that. Instead, our focus will be to compare and contrast oracle solutions by their designs, economics and strategies. We’ll cover live, sector leading projects, such as Chainlink and Band Protocol, in addition to promising newcomers, such as Pyth and API3. Before we dive into the specifics, we should preface that each of their designs is unique. As a result, efforts have been made to standardize how we explain the different parts to achieve a more “apples-to-apples” comparison cross protocol. Furthermore, these protocols are either not live yet (Pyth and API3) or have significant upgrades on their near-term roadmap (Chainlink V2 and Band Phase 2). At times, we might speak about upcoming changes as if they’ve already been implemented. In addition, oracles can submit more than pricing on-chain but to keep things simple, we’ll often just use “price” as a catchall term for data, since that is the lens most people already view oracle data through.
Let’s start by reviewing the diagram below, where we’ve created an abstract yet simplified view of each oracle relative to one another. While this diagram may look a bit different from what you’ll typically see in each protocol’s documentation, we’ve structured it this way to communicate a few key ideas -1) who are the stakeholders, 2) what are the economic underpinnings and 3) how does everything functions at a network level.
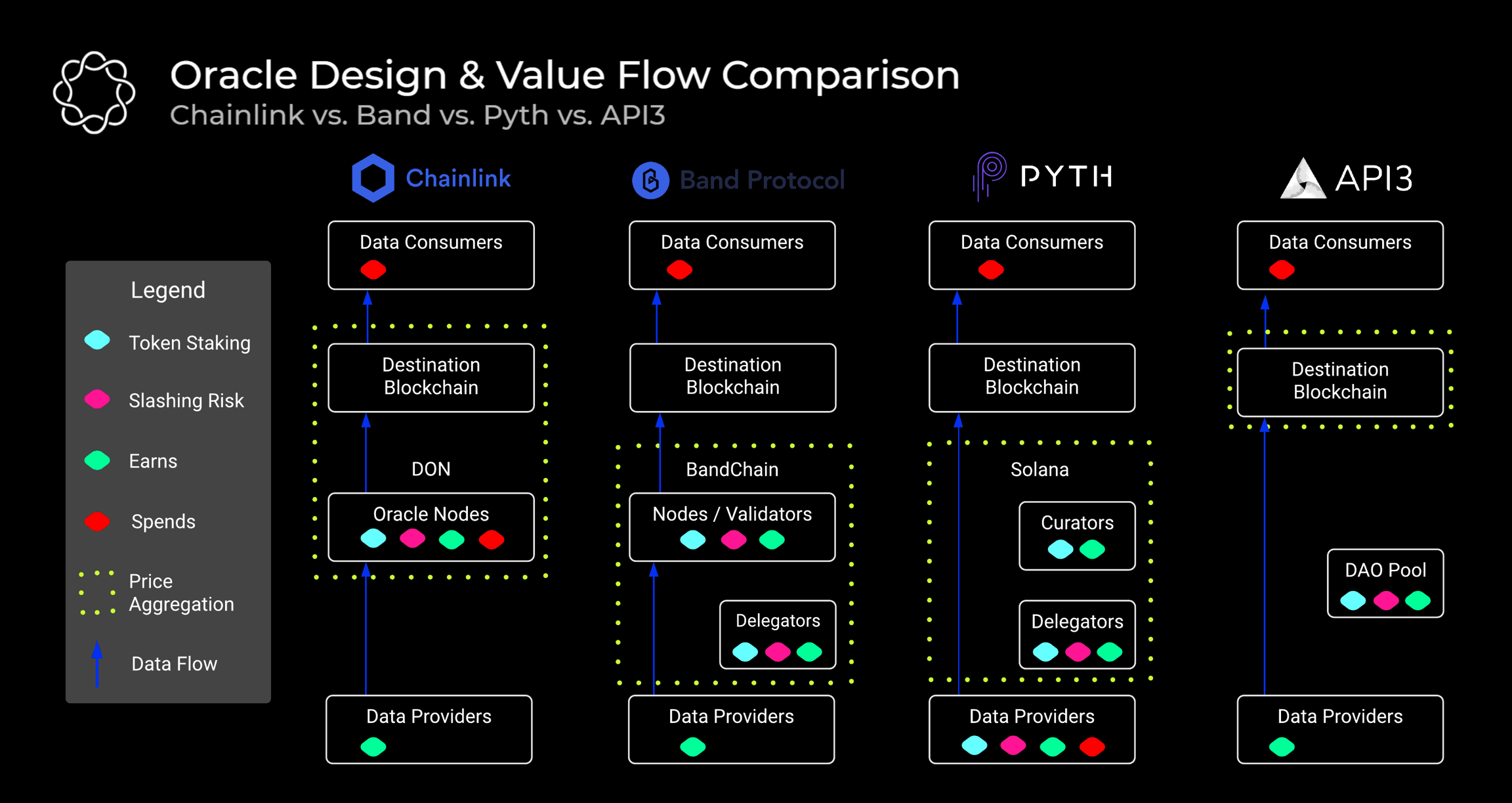
At the base of the diagram, we have arguably the most important group – the data providers. As the name implies, this is the source of the off-chain data. Now, a key distinction to be aware of is that this group includes both free and paid data sources. A good example of a free data provider is CoinGecko. At the top of the diagram we have the on-chain consumers of the data. Today, the consumers are mostly DeFi applications but in the future oracles will likely service a variety of diverse use cases. In between the source of the off-chain data and its on-chain consumption sits the oracle protocol.
A fundamental question for all oracle protocols – who submits data on-chain for aggregation? Depending on the oracle, the answer to that question will change. In the case of Chainlink and Band Protocol, this responsibility is carried out by third-party node operators. Third-party in this context means that they are not the originators of the data but rather they act as middlemen for pulling and submitting it. In contrast to this approach, Pyth and API3 were designed to remove the middlemen operators by having the data providers directly put their data on-chain. This distinction has important implications which we’ll discuss in greater detail further on in this report.
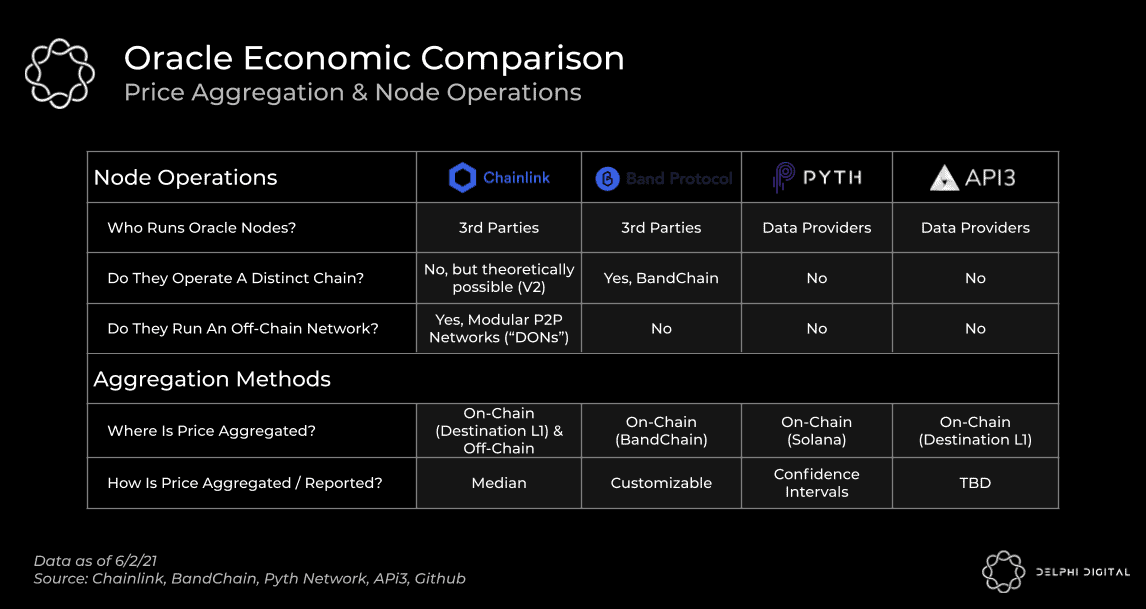
Band Protocol’s nodes operate a distinct blockchain (i.e. BandChain). When a request for data is submitted, the validating nodes fetch the data from its source, then aggregate and publish the information on BandChain as the network reaches consensus. Conceptually, Chainlink is similar but the nodes do not operate a distinct blockchain. Instead, Chainlink nodes come together to form off-chain P2P networks (i.e. Decentralized Oracle Networks, “DONs”). Furthermore, while Band Protocol has 1 validator set for its network, Chainlink can have several distinct node groupings, of varying sizes, all servicing different data feeds and chains.
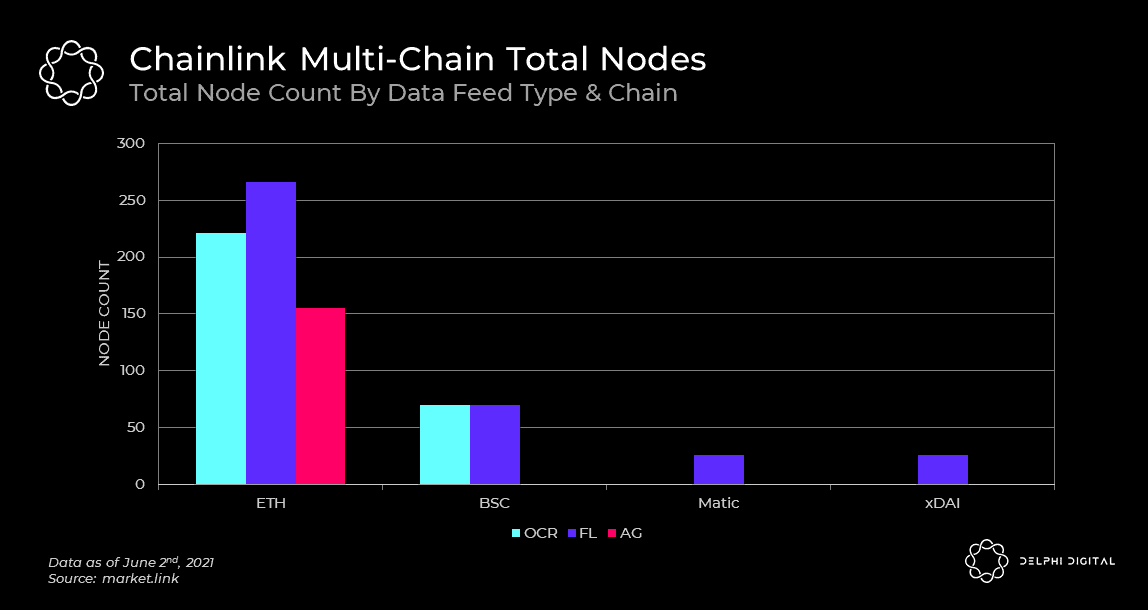
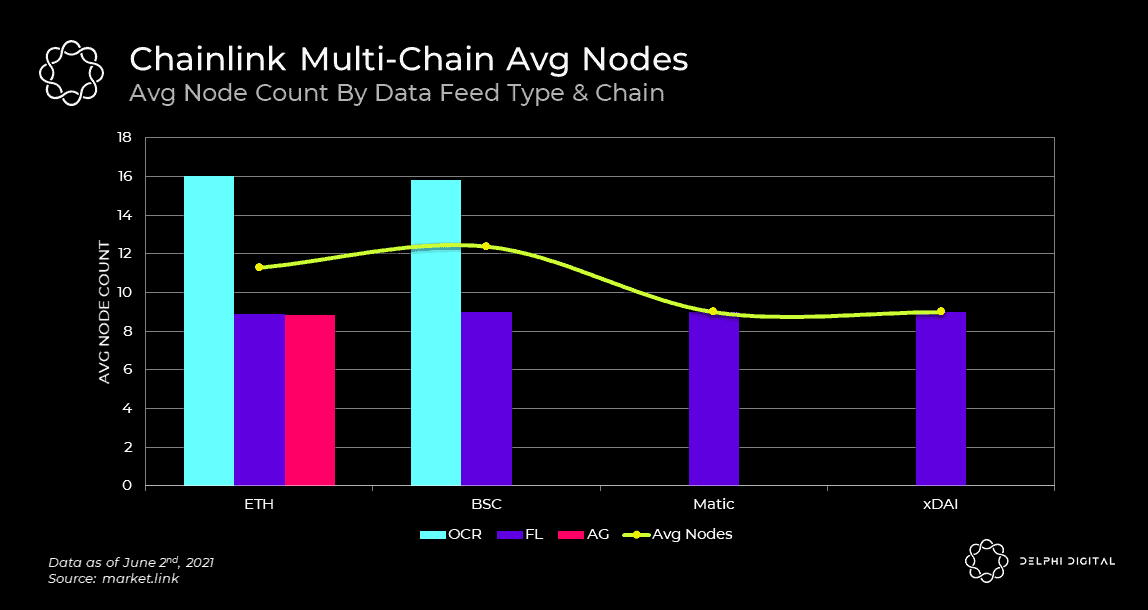
Chainlink is often touted as having hundreds of oracle nodes. While certainly true, only a small subset of the total nodes support each individual data feed and chain. For example, if we look at the chart below, the average number of nodes ranges from 9-12 depending on the chain. The implications of this will be important to consider when we reach the staking section later on in this report.
With Chainlink, data aggregation can occur on-chain (i.e. FluxAggregator “FL”) or off-chain (i.e. “OCR”), which has been reflected in the charts above and below (Note, “AG” is similar to FluxAggregator but has been deprecated). The main difference between the two methods is their gas cost. For on-chain aggregation, each oracle node needs to pay gas when they submit their price to the on-chain contract. For off-chain aggregation, only a single aggregated price is submitted on-chain. Basically, instead of having 21 oracle nodes all paying gas, only 1 needs to under the OCR method. On-chain aggregation, while an older approach, is still frequently used today despite the higher gas costs associated with it. However, on-chain aggregation is only the primary method on chains with lower gas costs.
Who bears the burden of paying gas and how expensive it is has a significant impact on the economic viability of an oracle solution, both in terms of operating an oracle node and paying to use its data feeds. It’s time to talk about the cost structure of oracle protocols. Revenue primarily comes from two sources – 1) consumers paying fees to use the data and 2) token rewards. The latter can help bootstrap a network but it’s the ability to collect the former that determines long-term sustainability. Operational costs aside, expenses typically boil down to 1) paying gas on-chain and 2) paying data providers. To better analyze these factors, let’s take a step back and start by looking at some data.
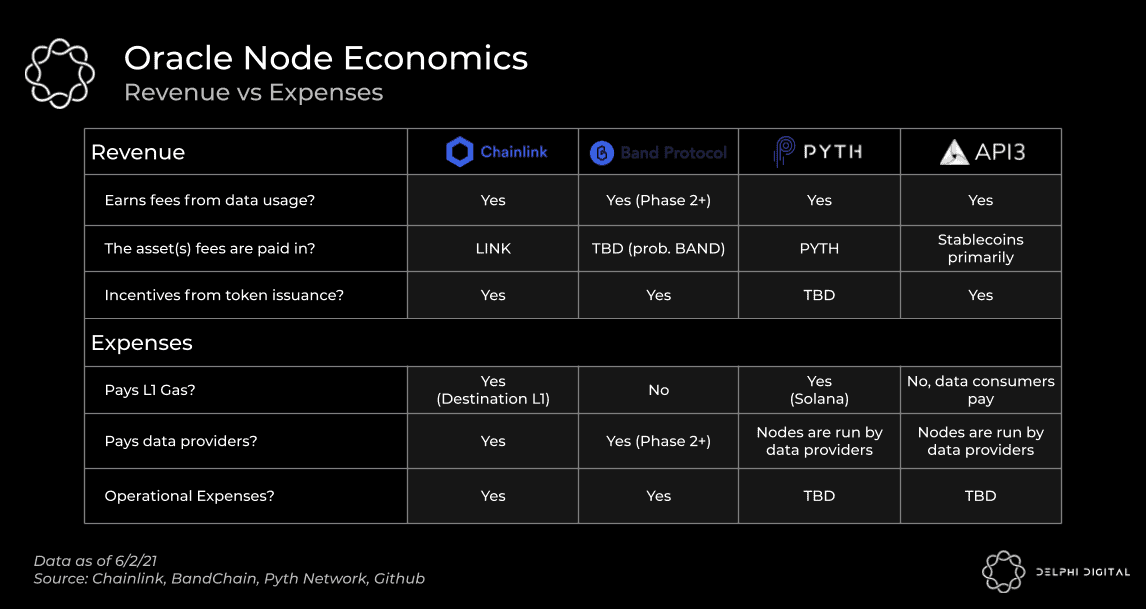
In the chart below, we’ve plotted the multi-chain profitability of LinkPool, a top Chainlink node, over the course of May using data from Chainlink Market. As you can see, total profitability ebbed and flowed materially at certain points in May. The days that sharply turned unprofitable all of the sudden occurred when gas fees spiked on the chains supported by LinkPool.
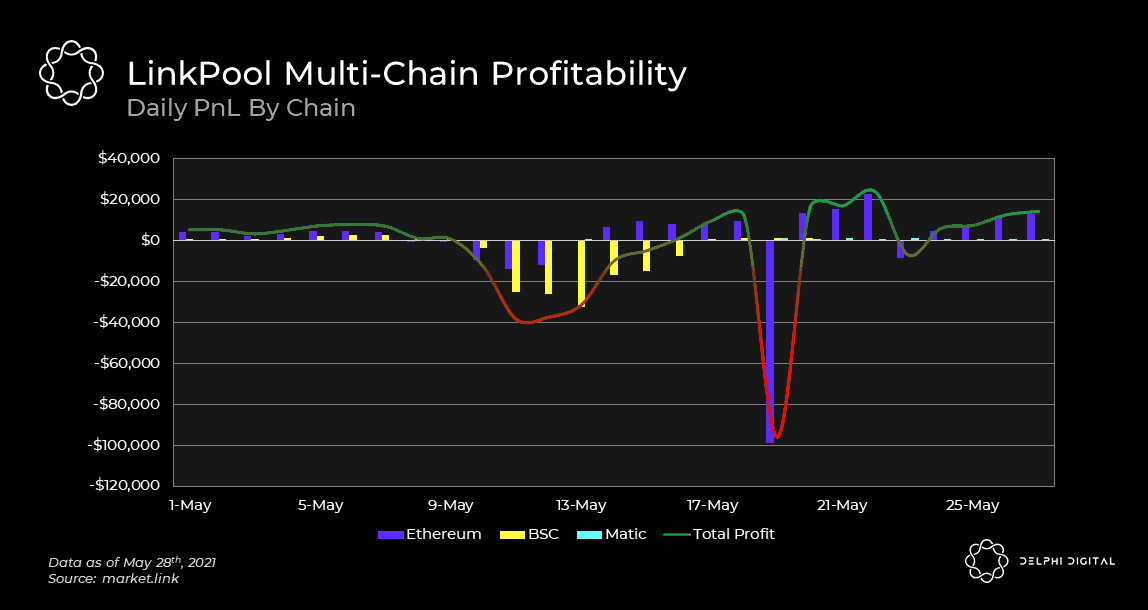
For a more summarized view of the timeframe in question, we’ve provided the chart below.
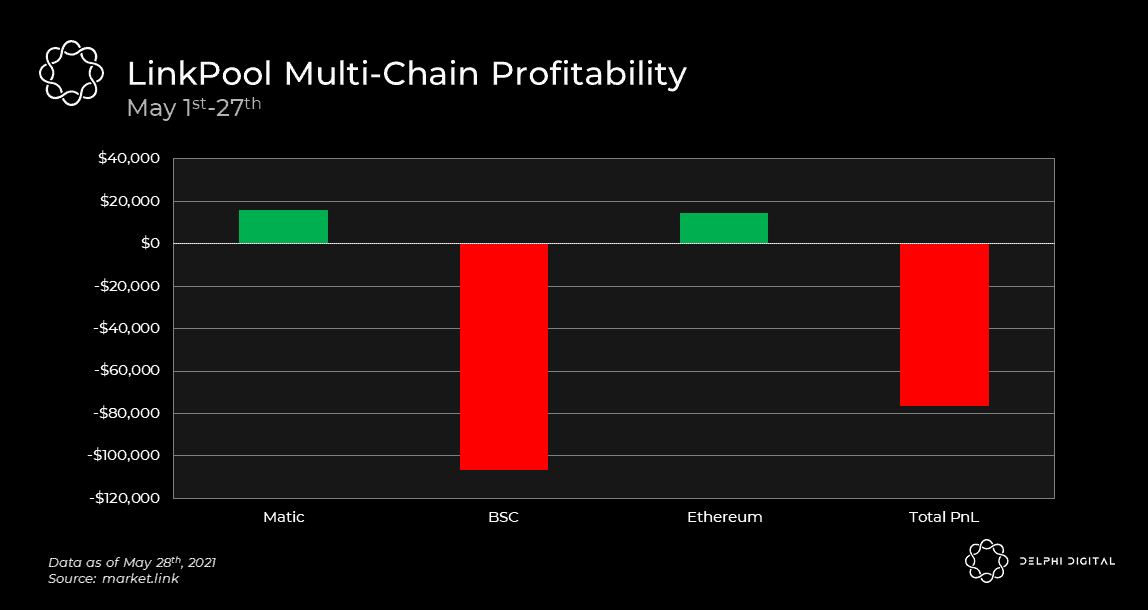
It’s evident that supporting data feeds on BSC was the determining factor which made May an unprofitable month for LinkPool. As you would expect from any rational actor, LinkPool has mostly ceased support for BSC following the event.
Even though gas fees on Ethereum reached absurd heights in May, LinkPool still eked out a decent profit of ~$15k on the chain. This begs the question – did high transaction fees or a lack of revenue make BSC so unprofitable in May? The answer is likely a combination of the two. Regardless, even if we isolate our analysis to only focus on Ethereum, it’s obvious that high gas costs hurt node profitability.
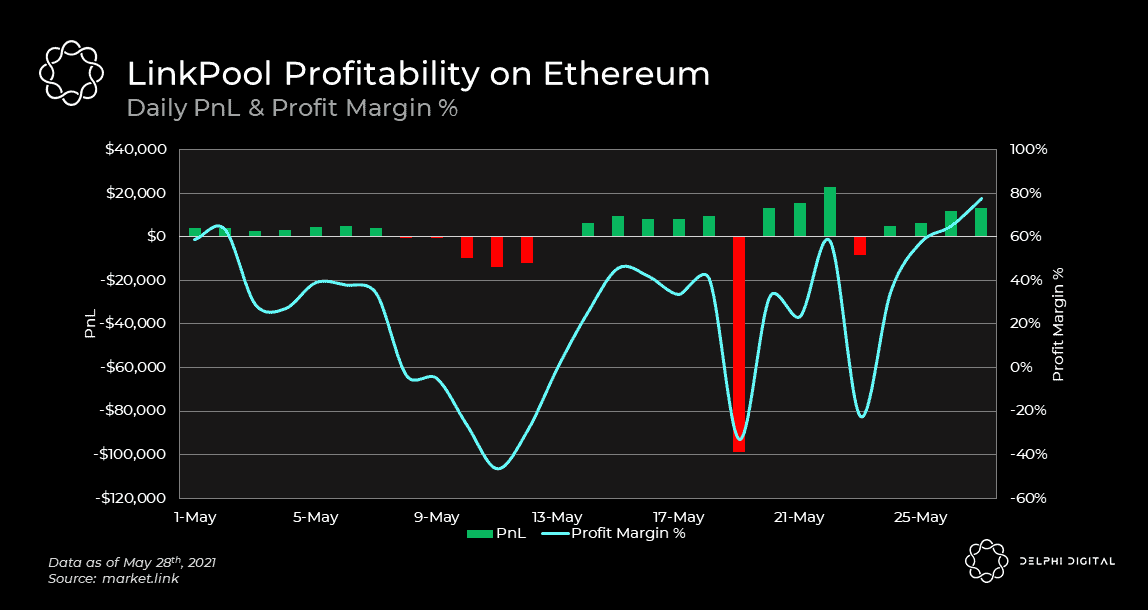
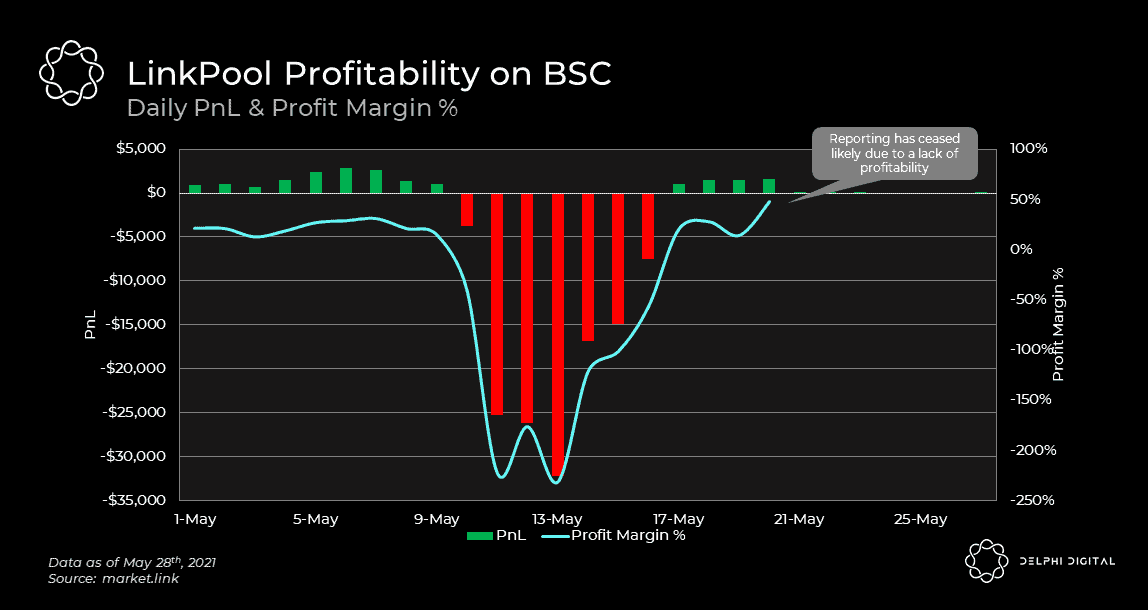
With this context in hand, let’s revisit the different aggregation methods we talked about earlier (i.e. on-chain vs off-chain). Off-chain aggregation, the cheaper approach by far, is the primary method used on Ethereum and BSC for major data feeds. However, despite this fact, those two networks still proved the most challenging to earn a profit on as an oracle node. In stark contrast to this, we have Matic. Even though all of the data feeds on Matic currently use on-chain aggregation, which is the more expensive method, it was the chain that generated the greatest profit and profit margin % for LinkPool. It wasn’t the revenue side of the equation that made Matic so profitable, it was the lack of gas costs that did. The advent of scalable layer 2s on Ethereum and alternative layer 1s help to alleviate Ethereum’s congestion, lowering gas costs for all. This is not only a boon for regular users but also oracle solutions too.
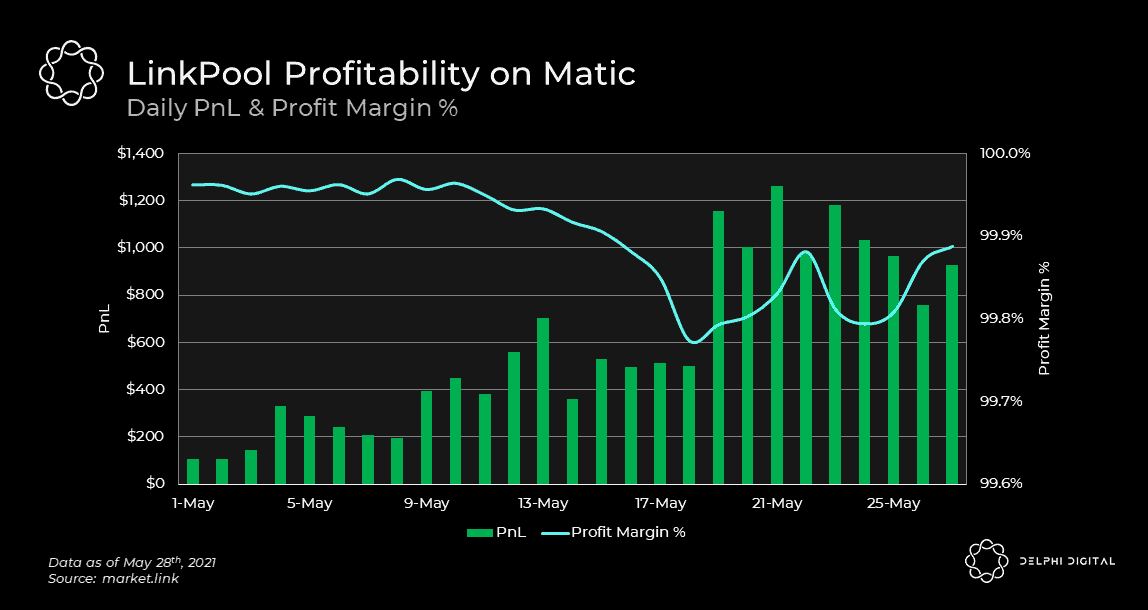
API3 and Pyth approach things differently by removing the Chainlink-style oracle nodes that sit in the middle of the stack. Instead, both aim to have data providers directly submit their prices on-chain for aggregation, rather than sending them to oracle nodes first. The goal with this design is to disintermediate the third-party oracles, improving profitability for the data providers themselves since they don’t have to share revenue with nodes anymore. However, as we’ve just demonstrated, submitting prices on-chain for aggregation can be costly. Will this prove to be a wise decision? As always, the answer to that question is in the details.
While Pyth does aggregate prices on-chain, and data providers pay the gas costs associated with it, the important thing to realize is that the chain is Solana. The scalability of the network enables a low fee environment which makes the associated gas costs a non-issue. In this case, the profit margin potential should be more similar to Matic rather than Ethereum L1. The tricky part here is how the aggregated prices are communicated from Solana to the other chains where demand to use the data exists. To accomplish this communication, Pyth will rely on Wormhole. While certainly promising, it’s too early to opine on the costs and attributes associated with this component because we haven’t seen Pyth use it live on mainnet yet. If successful though, Solana should enable Pyth to have an attractive cost structure, strong network security assurances for price aggregation and fast update speeds (~400ms block times).
API3 is similar with regards to how data providers directly submit their data on-chain, but the with one major difference – it’s the consumers of the data that pay the gas fees. Theoretically, this can make a lot of sense because it reduces the cost burden on data providers, lowering the barriers to entry, and making it more attractive for new data providers to onboard (more on this soon). This is a potential benefit for the supply side, however, it can have its drawbacks. Without off-chain aggregation, if the on-chain consumers need to pay for each data provider’s gas bill, API3’s solution could look prohibitively expensive to consumers, hurting the demand side. Whether or not that is actually the case will depend on which chain the consumers live, how many data providers they want to pull for a specific feed and how frequently the updates need to occur. Could this eat away at Chainlink’s market share on Ethereum L1? If consumers don’t want to rely on a single pricing source, perhaps not. Could it compete on Solana, Matic and layer 2s? Certainly.
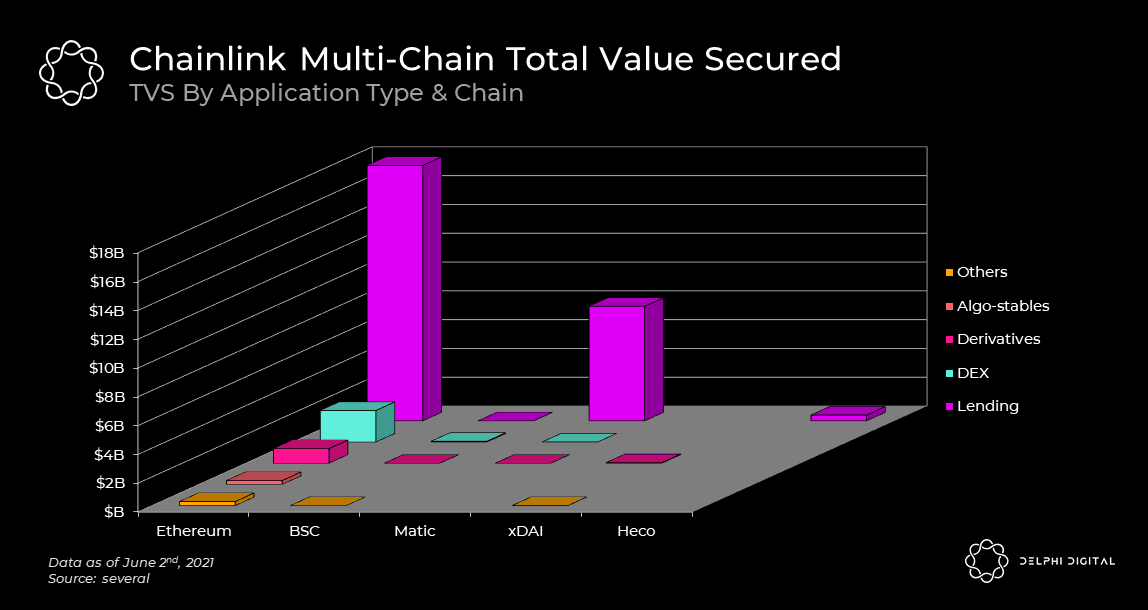
The hardest part about building an oracle protocol is the security. Namely, how do you create a decentralized, economically secure solution that is resistant to price manipulation? Lending protocols rely on its price feeds to determine whether or not a borrower needs to go into liquidation. Derivative protocols rely on its price feeds to ensure positions and payouts are marked accordingly. To understand the scale of the problem, let’s take a look at the amount of value reliant on these data feeds. In the chart below, we’ve broken out the total value secured by Chainlink across different application types and chains. In total, Chainlink secures ~$30b at the moment. With all this money on the line, how do you prevent a small group of anon node operators with nothing on the line from manipulating markets to their benefit?
To solve for this, you might be thinking – “why not just implement staking and penalize inaccurate pricing?”. This is a logical conclusion to jump to because, with cryptoeconomics, that has so often become the answer lately. But with oracles it’s far trickier. Let’s explain why with an example. Imagine you have a data feed that secures billions of dollars in derivatives and has 9 staked validators supporting it. An opportunity arises where, if that data feed is manipulated a certain way at the right time, it could inappropriately trigger a derivative to payout $1b. In this situation, 5 oracles (i.e. the majority) could position themselves accordingly in the market, manipulate the price feed they operate, trigger a payout to themselves and walk away with a handsome return. A return that is orders of magnitude higher than the value they have staked and could earn being an honest actor from fees. At this point you might be thinking – “wouldn’t those misbehaving oracles have their stake slashed?”. Well, no. Those 5 oracle nodes ARE the “source of truth” since they are in the majority. Not only are they not slashed, the 4 honest oracle nodes actually would be for reporting the correct price because it deviated from what the majority submitted.
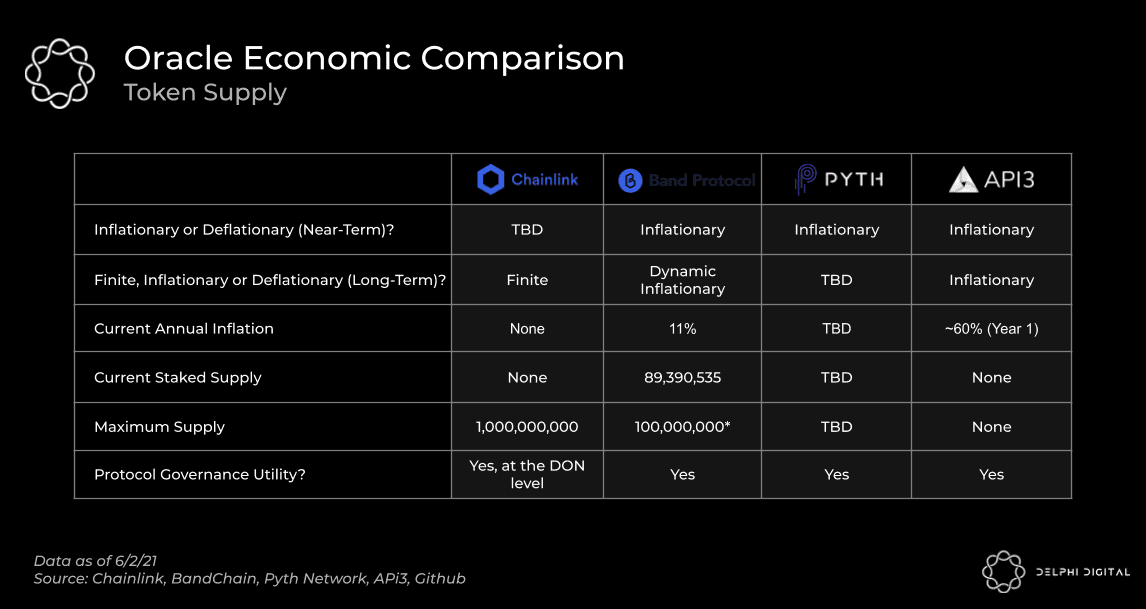
Herein lies the issue with slashing staked nodes for inaccurate pricing. It’s one of the main reasons why Chainlink hasn’t already implemented staking. This will change, however, with the launch of Chainlink V2, which plans to add support for it. For an overview of the many obvious issues with their proposed staking design, we recommend reading Eric Wall’s recent post on it. This isn’t to say that everything mentioned in their v2 whitepaper lacks merit though. The Fair Sequencing Services (FSS) and hybrid smart contract stuff could be interesting. With that said, we do have questions about whether or not they’re actually an improvement over what they’re trying to solve for in the first place. One of their stated goals in the paper is trust minimization but our view after reading it is that most of their suggestions actually require greater trust. In many cases, you might trade the trust you place in miners/validators to the oracle node operators instead. Is that actually better and, in lieu of true layer 2s starting to emerge, what’s the point?
Staking, in one form or another, is likely necessary though, if for no other reason than to align incentives and make the oracle solution more sybil-resistant. Will the staked value be enough to truly secure the data feeds? After much debate between members of our team, we’re not sure if attaining that is feasible, or even economically viable. In the absence of it, we believe that reputation will be vital to security, perhaps moreso for oracles than any other sector in crypto. With this in mind, one aspect we like about Pyth and API3 is that the data providers themselves are the ones placing their reputation on the line. If prominent firms participate, it will go a long way to improving the trust consumers place in their oracles relative to the third-party operators seen in Chainlink and Band Protocol. Furthermore, the fact that the majority of Chainlink nodes are completely anonymous is less than ideal. However, Chainlink’s DECO and Town Crier solutions, as outlined in the V2 whitepaper, could allow third-party node operators to prove that they haven’t tampered with the data they received from its source.
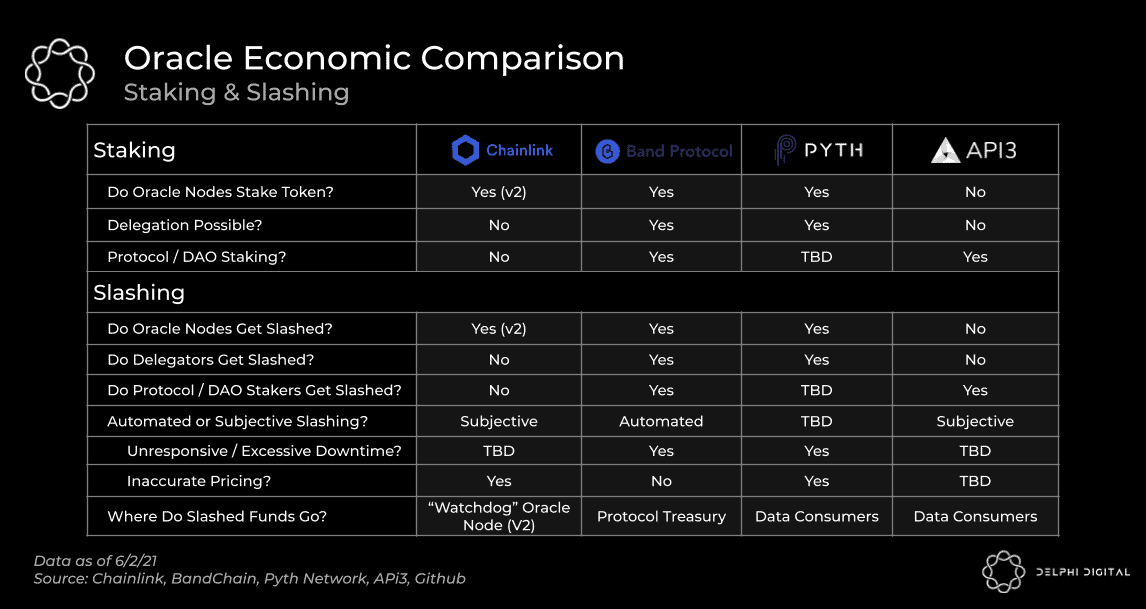
An important aspect we like about Pyth and API3 is that the data consumers are the ones who get paid out when a slashing event occurs. After all, those applications and their users are the ones who lose when the oracles they rely on misbehave. This won’t be the case with Chainlink because its v2 design needs that slashed value to pay out the “watchdog” oracle node as a reward for spotting misbehavior (see Eric Wall post). Pyth is staked by data providers, and those who delegate to them, in order to secure their respective data feeds. While delegation is not always needed, incorporating it here does bring the added benefit of increasing the value at risk, and thus the amount of value data consumers can expect to receive as compensation in the event of slashing. API3 is structured a bit differently. Individual data providers / third-party oracle nodes do not stake its token to participate. Instead, staking is done at a protocol DAO level. The downside here is that the entities responsible for providing the data are not penalized for misbehaving. However, there is a benefit to this approach. Namely, it’s a lot easier to onboard new data providers when they don’t have to go out and buy your token first. Let’s explore this last point further because it’s an important one.
If an oracle relies solely on free, publicly available information it’s in danger of not bringing anything unique to the table. There are many ways the end consumer could go around and cut them out of the equation, whether through a competing solution that has more to offer or simply pulling the data directly yourself (like how Compound does it). Currently, Band Protocol is the only live oracle solution covered in this report that is completely reliant on free data sources, however, this will change as ‘Phase 2‘ of their roadmap is implemented heading into year end.
If private, proprietary data sources are a moat, how can these oracle solutions onboard them? Let’s start with Chainlink because there are really two distinct roles they want to recruit for – data providers and oracle nodes. For data providers, the main benefit of onboarding is the ability to monetize their data by working with Chainlink to put it on-chain. This can be a lucrative opportunity, but are they leaving money on the table by sharing revenue with oracle node operators? Indeed, this realization was partly the impetus for why Pyth and API3 were launched. Disintermediate the middlemen, boost profitability for the data providers.
Onboarding new oracle nodes is a different challenge and one that is potentially made worse by requiring them to stake. Earlier, we demonstrated how operating an oracle node can be unprofitable due to high gas costs. The uncertainty associated with this can be tough to stomach although it should improve when servicing scalable networks. If the sales pitch to new node operators also requires them to go out and buy your expensive token to lock it up, that adds an entirely new risk vector though. At that point, it’s not the operating losses you’re worried about, but rather a declining LINK price hurting the value you have staked (slashing aside). For Chainlink, the only solution we see is for them to give away their token as an incentive to onboard new entities. Prudently, 35% of their token supply should be reserved for just that.
However, as we already outlined, onboarding node operators is not the same as onboarding new data providers. The two aren’t just competing for fees in Chainlink’s design, they’re also competing for token incentives. Pyth is going right to the source, onboarding TradFi institutions and, most importantly, their data into crypto. A notable example of this is the recent addition of GTS which accounts for 3–5% of daily cash equities volume in the US.
Chainlink has long dominated the oracle sector. It would be foolish to discount its network effects given the vast number of integrations it already has in place. What’s exciting to us, is that viable competition in that sector may finally be starting to emerge, with differentiated designs backed by big players. While we view the oracle sector as a “winner-take-most” situation, the TAM is so large that even being a runner-up is a success in its own right. If you’re like us though, then you aren’t focused on 2nd place. We hope the analysis contained in this report leaves you better equipped to figure out who the winner could be for yourselves.
Last updated